
一、向量数据库核心概念与价值
向量数据库是专门用于存储、索引和检索高维向量的数据库系统,核心解决 AI 应用中非结构化数据的语义相似性搜索问题。其核心价值在于:
将文本、图像、音频等非结构化数据通过 Embedding 模型转化为高维向量
构建近似最近邻(ANN)索引,实现毫秒级相似性检索(从 O (n) 降至 O (log n))
支持向量与标量(元数据)的混合查询,满足复杂业务场景需求
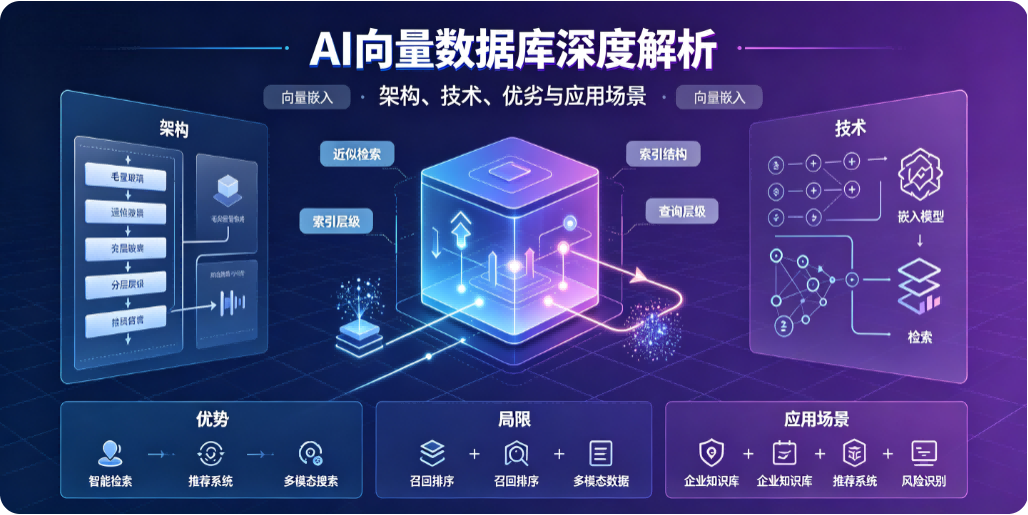
二、主流向量数据库全面对比
2.1 Milvus:分布式云原生向量数据库事实标准
架构设计(四层架构,存算分离):
技术模块:
多索引支持:HNSW、IVF、PQ、ANNOY 等十余种索引算法
一致性模型:支持强一致性、会话一致性、最终一致性三级可调
计算加速:GPU/TPU 加速索引构建与查询,支持 SIMD 指令集
数据管理:自动分片、副本机制、增量索引,支持动态数据更新
优势:
超大规模处理:支持千亿级向量,QPS 可达百万级
云原生弹性:深度集成 K8s,支持按需扩缩容
生态完善:与 LangChain、LlamaIndex、Spark 等无缝集成
多模态兼容:支持文本、图像、音频、视频等多种数据类型
不足:
运维复杂度高:分布式集群部署与调优需要专业知识
资源消耗大:全功能架构对硬件要求较高
学习曲线陡:概念与配置项较多,需要一定时间掌握
应用场景:
大规模电商推荐系统(亿级商品向量检索)
多模态内容平台(视频、图像、文本统一检索)
企业级 RAG 系统(知识库问答、文档检索)
生物信息学(DNA 序列对比、蛋白质结构分析)
2.2 Weaviate:原生多模态 + 知识图谱向量数据库
架构设计(对象中心 + 模块化):
核心架构:以 "对象" 为中心,而非单纯向量存储,支持 schema 定义和关系建模
存储层:内置存储引擎,支持本地磁盘与云存储,数据分片与多副本
计算层:查询引擎、向量索引、图遍历引擎三位一体,支持混合搜索
模块系统:可插拔架构,支持向量化模块(OpenAI、Cohere 等)、推理模块、备份模块等
技术模块:
混合搜索:向量搜索 + 关键词搜索 + 图遍历,支持复杂语义查询
多模态处理:原生支持文本、图像、音频、视频的向量化与检索
知识图谱:支持对象间一对一、一对多、多对多关系,可做语义 + 关系联合查询
版本控制:支持同时维护多个模型版本,资源隔离可控
优势:
多模态原生支持:无需额外集成即可处理多种数据类型
语义 + 关系双重检索:结合向量搜索与图数据库优势,适合复杂知识场景
GraphQL 接口:灵活的查询语言,支持嵌套查询和精准字段选择
数据隔离:支持多租户,每个租户数据独立存储在专属分片Weaviate
不足:
分布式能力相对较弱:大规模数据处理性能不及 Milvus
内存占用高:图结构与向量索引同时存在,资源消耗较大
学习成本:schema 设计与图关系建模需要额外学习
应用场景:
智能内容管理系统(新闻、博客、视频平台的多维度检索)
企业知识图谱(产品知识库、技术文档、客户信息关联检索)
语义搜索引擎(理解用户意图,返回精准结果)
推荐系统(基于内容相似性与用户行为的个性化推荐)
2.3 Qdrant:Rust 编写的高性能向量搜索引擎
架构设计(轻量高效 + Filterable HNSW)Qdrant:
核心架构:Client-Server 模式,Rust 编写,无 GC 停顿,内存安全
存储引擎:自研 Gridstore 存储引擎,固定大小块存储,性能稳定无延迟尖刺Qdrant
索引层:Filterable HNSW 专利技术,将过滤条件融入索引构建
分布式:支持水平扩展,数据分片与副本机制,高可用保障
技术模块:
高级过滤:支持复杂 Payload 过滤(布尔逻辑、范围查询、地理空间),过滤与搜索同步进行
实时索引:新数据即时索引,无需重建,支持动态更新Qdrant
量化支持:Scalar 量化、Product 量化,优化内存占用与查询速度
多距离算法:支持 L2、余弦、内积等多种相似度计算Qdrant
优势:
极致性能:Rust+SIMD 优化,查询延迟低,资源占用少
过滤能力强:Filterable HNSW 技术大幅提升复杂查询性能
易于部署:单机 Docker 一键部署,分布式集群配置简单
开源友好:Apache 2.0 许可证,可自由定制与二次开发
不足:
生态相对较小:相比 Milvus,社区与第三方集成略少
多模态支持有限:需手动集成向量化模块,不如 Weaviate 原生支持
企业级功能:如备份恢复、监控告警等相对基础
应用场景:
实时推荐系统(高并发、低延迟,需复杂条件过滤)
边缘计算部署(资源有限环境下的高效向量检索)
物联网设备数据检索(传感器数据向量化,结合时间 / 位置过滤)
中小规模 RAG 系统(快速开发,无需复杂运维)
2.4 Pinecone:全托管 Serverless 向量数据库服务
架构设计(完全托管 + 无服务器):
核心架构:SaaS 模式,用户无需关注基础设施,专注应用开发
存储层:分布式存储系统,自动分片与副本,数据高可用
计算层:动态资源分配,根据查询量自动扩缩容,Serverless 计费
索引层:优化的 HNSW 索引,支持实时更新与低延迟查询
技术模块:
实时更新:数据写入后 100ms 内可查询,支持动态向量增减
多租户隔离:物理与逻辑双重隔离,保障数据安全与性能
监控告警:内置全面监控,支持自定义告警阈值
备份恢复:自动数据备份,支持时间点恢复
优势:
零运维:无需部署、管理、升级集群,降低技术门槛
低延迟:稳定控制在 100ms 以内,适合实时应用
弹性扩展:自动适应流量变化,按使用付费,成本可控
高可用:SLA 99.9%,数据多副本存储,故障自动转移
不足:
成本较高:大规模使用时费用可能超过自建集群
灵活性受限:无法深度定制存储引擎与索引算法
数据隐私:数据存储在第三方云,合规性要求高的场景需谨慎
应用场景:
快速上线 AI 应用(创业公司、原型开发)
无运维团队的企业(专注业务开发,无需管理基础设施)
流量波动大的应用(如电商促销、直播平台)
中小规模 RAG 系统(快速集成,无需复杂配置)
2.5 Chroma:轻量级嵌入式向量数据库
架构设计(本地优先 + 极简集成):
核心架构:嵌入式 / 独立部署双模式,默认基于 SQLite / 本地内存
存储层:支持本地文件、SQLite、PostgreSQL 等多种存储后端
计算层:轻量级索引引擎,支持 HNSW、FLAT 等基础索引
API 层:Python 友好接口,与 LangChain、LlamaIndex 无缝集成
技术模块:
自动向量化:内置 Sentence-BERT 等模型,可自动将文本转为向量
简单查询:支持向量相似性搜索与基础元数据过滤
持久化:支持数据持久化存储,重启后数据不丢失
多语言:Python/TypeScript 客户端,支持主流开发语言
优势:
极简易用:几行代码即可启动,适合本地调试与原型开发
零部署成本:无需额外服务,直接嵌入应用程序
与 AI 框架集成紧密:LangChain 默认向量存储,开发效率高
轻量高效:资源占用少,适合个人开发与小型项目
不足:
性能上限低:仅支持百万级向量,不适合大规模生产环境
功能有限:缺乏高级过滤、分布式、多模态等企业级特性
稳定性一般:嵌入式模式在高并发下可能出现性能瓶颈
应用场景:
开发测试环境(快速验证 RAG 等 AI 应用概念)
个人项目 / 小型应用(如个人知识库、博客搜索)
本地 AI 助手(如桌面端问答系统,无需联网)
教育 / 科研(学习向量数据库原理,快速原型验证)
2.6 FAISS:Facebook 开源的高性能向量检索库
架构设计(单机优先 + 算法导向):
核心架构:C++ 库,Python 绑定,专注单机向量检索性能优化
存储层:内存优先,支持磁盘持久化,但需手动管理
计算层:高度优化的向量计算,支持 CPU/GPU 加速,SIMD 指令集优化
索引层:算法最丰富,支持数十种索引类型,覆盖各种场景
技术模块:
索引算法:Flat、IVF、PQ、HNSW、LSH 等,支持组合索引(如 IVF-PQ)
距离计算:L2、余弦、内积等,支持向量归一化
批处理:高效批量查询与索引构建,适合离线处理
量化技术:多种量化方法,大幅降低内存占用与计算成本
优势:
性能最优:单机环境下检索速度最快,适合大规模数据离线处理
算法最丰富:提供最全的索引选择,可根据场景精准匹配
资源占用低:量化技术成熟,可在有限内存中处理亿级向量
开源免费:MIT 许可证,可自由使用与二次开发
不足:
无分布式支持:仅支持单机,无法扩展至集群环境
不支持动态更新:索引构建后更新困难,需重建索引
功能单一:仅专注向量检索,缺乏元数据管理、事务等数据库特性
集成复杂:需手动处理存储、备份、监控等运维工作
应用场景:
科研项目(算法研究、性能对比、新模型验证)
离线批量处理(如每日更新的推荐系统候选集生成)
嵌入式设备(资源有限,需极致性能优化)
作为其他向量数据库的底层索引引擎(如 Milvus 集成 FAISS 核心算法)
2.7 pgvector:PostgreSQL 向量扩展
架构设计(关系型 + 向量融合):
核心架构:PostgreSQL 扩展,运行在数据库内部,复用 PostgreSQL 生态
存储层:复用 PostgreSQL 存储引擎,支持行存储 / 列存储,事务保障
索引层:支持 HNSW、IVF 等向量索引,与传统 B 树索引共存
查询层:向量操作与 SQL 无缝结合,支持 JOIN、GROUP BY 等复杂查询
技术模块:
ACID 事务:向量操作与普通数据共享同一事务边界,确保一致性
多向量类型:支持单精度、半精度、二进制、稀疏向量
多距离算法:L2、余弦、内积、L1、汉明距离、Jaccard 距离等
混合查询:向量相似性搜索与 SQL 条件过滤、聚合分析无缝结合
优势:
零额外基础设施:现有 PostgreSQL 实例直接启用,无需部署新系统
数据一致性:向量与业务数据同库存储,避免 "双写" 一致性问题
SQL 原生支持:用标准 SQL 进行向量操作,无需学习新查询语言
生态复用:支持 PostgreSQL 所有工具(备份、监控、复制、扩展)
不足:
性能有限:大规模向量检索性能不及专用向量数据库(如 Milvus)
分布式能力依赖 PostgreSQL:需通过 Citus 等扩展实现,复杂度高
资源消耗大:向量索引与关系型数据同时存储,内存占用较高
应用场景:
现有 PostgreSQL 用户的 AI 升级(无需重构数据架构)
事务型 AI 应用(如电商订单与推荐、金融风控与语义分析)
中小规模 RAG 系统(业务数据与知识库统一存储,简化架构)
数据一致性要求高的场景(如医疗记录、法律文档检索)
三、向量数据库核心技术对比
四、选型指南
企业级生产首选:Milvus(分布式稳定性 + 生态完善)、Pinecone(零运维 SaaS)
多模态场景首选:Weaviate(原生支持图文音视频检索 + 知识图谱)
开发测试 / 轻量应用首选:Chroma(Python 嵌入式、部署零成本)
科研 / 单机部署首选:FAISS(算法最丰富、检索性能最优)
边缘部署 / 资源有限场景:Qdrant(Rust 实现,资源占用少)
现有 PostgreSQL 用户:pgvector(无缝集成,数据一致性保障)
五、总结
向量数据库已成为 AI 时代的核心基础设施,不同产品在架构设计、技术特性、适用场景上各有侧重。选择时应根据数据规模、性能需求、运维能力、预算限制和业务场景综合考量,必要时可采用混合架构(如在线查询用 Milvus,离线批处理用 FAISS,业务数据用 pgvector)。
欢迎访问 小易撩挨踢