
按底层开发、一键微调、训练加速、数据处理、训练监控、云端训练、推理配套7 大类划分,覆盖个人单卡微调→企业多卡预训练全场景,优先选开源易用、社区成熟工具。
一、底层基础开发库(自研 / 手写训练脚本必备)
1. Hugging Face 全家桶(行业标配)

HuggingFace生态
Transformers:加载百种开源大模型 (Qwen/Llama/ChatGLM/Mistral/Gemma),统一 API 做推理、微调,底层训练基石。
PEFT:参数高效微调核心库,原生支持 LoRA/QLoRA/IA3,不用全量更新权重,单卡即可微调 7B 模型。
Datasets:数据集标准化加载、清洗、分片,内置上千开源语料。
Accelerate:一行代码自动适配单卡 / 多卡 / 混合精度,不用手写分布式逻辑。
适用:想自主编写训练代码、算法实验。
2. PyTorch
深度学习底层框架,动态图调试友好,绝大多数大模型基于 PyTorch 开发;搭配torch.cuda、混合精度做基础训练调度。
二、一站式无代码 / 少代码微调框架(90% 从业者首选,不用手写训练逻辑)
1. LLaMA Factory(综合全能 TOP1)
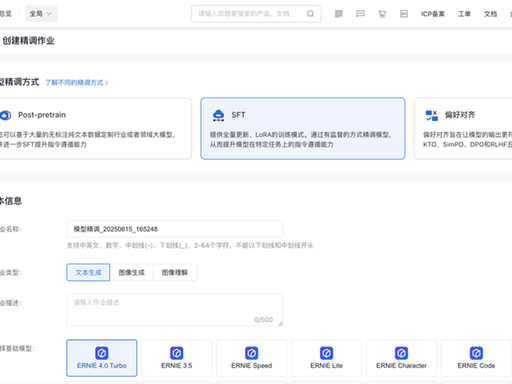
核心:Web 可视化界面 + 命令行双模式,支持 SFT 监督微调、DPO/PPO/KTO 强化对齐、全参微调、LoRA/QLoRA,覆盖百款主流大模型(通义千问、Llama2、GLM、Mistral)。
亮点:内置 FlashAttention/Unsloth 加速、一键 LoRA 权重合并、训练中在线对话测试、导出 OpenAI 格式 API;Docker 一键部署开箱即用。
适用:行业知识库微调、私有化定制大模型、RLHF 全流程落地(个人 / 中小企业通用)。
2. MS-Swift(阿里开源,主打 Qwen 系列)
阿里达摩院开源,深度优化通义千问全系列模型,配置化训练,一键 QLoRA 微调,适配国产 GPU / 昇腾 NPU,多模态图文大模型微调友好。
3. Axolotl(配置驱动极简微调)
靠YAML 配置文件完成全流程,无需大量代码,内置 xformers、FlashAttention、LigerKernel 加速,预存大量主流模型微调配方,适合批量实验、快速迭代 LoRA 方案。
4. Unsloth(单卡微调速度天花板)
极致优化 QLoRA/LoRA,同等硬件下微调速度比原生 PEFT 快 2~4 倍、显存占用减半,单张 16G 显卡轻松微调 7B 全量 LoRA,主打轻量化快速微调。
三、多卡 / 集群训练加速框架(7B + 大模型多机分布式、预训练)
1. DeepSpeed(微软开源)
ZeRO 优化技术标杆,显存卸载、模型分片,多卡 / 多机大幅降低超大模型 (13B/34B) 训练显存门槛,LLaMA Factory、Axolotl 原生集成。
2. Megatron-LM(英伟达)
千亿参数大模型预训练专用,模型并行 + 流水线并行,超大规模基座预训练首选(科研大厂自研基座使用)。
3. FSDP(PyTorch 原生)
PyTorch 官方分布式方案,轻量化、生态无缝,中小规模多卡训练替代 DeepSpeed。
四、数据集处理工具(训练数据清洗、格式化)
OpenRLHF-Datasets:指令微调数据集格式化,自动转为 SFT/RLHF 标准格式。
Textbox/LLMDataFactory:中文语料清洗、去重、过滤低质文本,批量生成问答指令数据集。
ModelScope-Datasets:阿里魔搭海量开源中文数据集一键下载。
五、训练日志 & 可视化监控工具
TensorBoard:训练 Loss、学习率、显存占用本地可视化,通用免费。
Weights & Biases(WandB):云端训练看板,远程查看多机训练曲线、版本管理,小项目免费额度够用。
MLflow:实验全生命周期管理,记录参数、权重、数据集,企业实验管理。
六、云端 Serverless 训练平台(无本地 GPU,按需
(阿里)Twinkle:组件化训练工作台,Serverless 免自备 GPU,一键微调 Qwen 等国产模型,代码无缝迁移本地部署。
Gitee AI 模力方舟:按需租用 GPU,可视化拖拽微调,兼容 LLaMA-Factory,按量计费,中小团队快速试错。
AWS SageMaker:企业级全链路训练,对接 LLaMA Factory 做云原生微调部署。
七、训练后推理加速配套(微调完部署上线)
vLLM:PagedAttention 推理加速,微调后模型一键部署高并发 API,吞吐量提升数倍。
Text Generation Inference(TGI):HuggingFace 官方生产级推理服务。
llama.cpp:CPU / 边缘设备量化部署微调后的 LoRA 模型。
快速选型建议
个人单卡 (16G/24G) 微调知识库:LLaMA Factory + Unsloth + QLoRA
批量快速做实验:Axolotl (YAML 配置)
深度自研模型、从零预训练:Transformers+PEFT+DeepSpeed
无本地显卡、临时训练:ModelScope/Gitee AI 云端微调
通义千问全系定制:MS-Swift