
一、可行性分析
可信数据空间(TDS)的接入连接器,与数据流(Stream)深度融合,才能满足实时、合规、高效的数据流通需求。
(一)现有模式:文件/数据库DB/API的弊端
只能做离线批量,无法支撑实时业务
合规与安全无法随流管控,存在数据泄露风险
数据流通效率低、延迟高,尤其对于高质量数据集流通实时性失去数据空间核心价值
不符合国家标准与行业的最佳实践,且应对客户的复杂业务需求难以支撑。
(二)必要性分析
1.业务场景刚需
实时场景:金融风控、工业 IoT、智慧交通、供应链协同,都要求秒级 / 毫秒级数据流转
合规要求:数据使用控制、审计、溯源,必须随流执行、全程可追溯
数据主权:数据不出域、可用不可见,流处理 + 隐私计算是唯一可行路径
2.连接器的原生定位
连接器是数据空间的守门人 + 数据管道,必须同时支持批量 / API/Stream三种交付模式
标准明确要求:接入连接器需支持批量数据流、实时流(Kafka/Pulsar) 接入与交付
3.技术架构强绑定
连接器向下对接数据源(DB/API/ 消息队列),向上对接服务平台与跨域连接器
Stream 是高吞吐、低延迟、持续数据的唯一载体,是连接器的核心数据通道
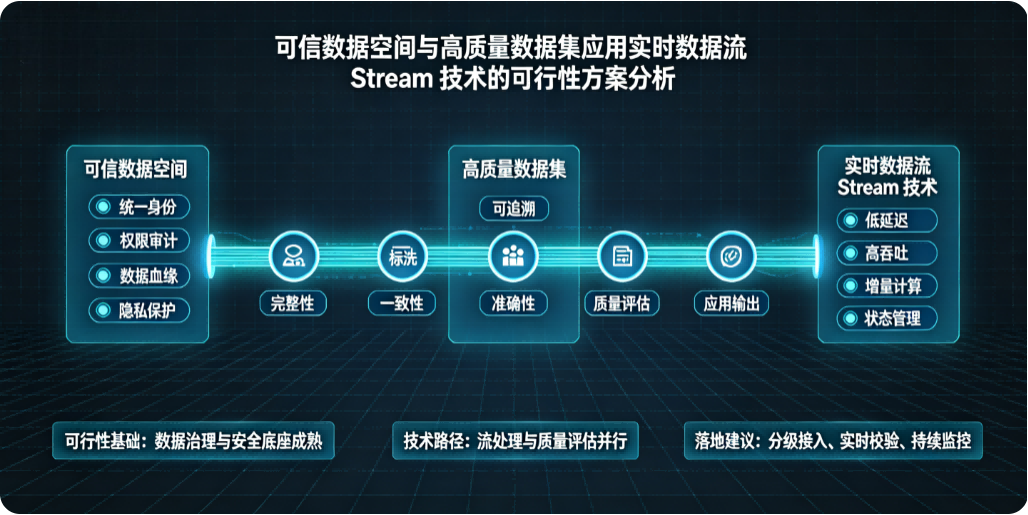
二、可信数据空间与高质量数据集的结合诉求
高质量数据集的构建、清洗、标注、入库,几乎都离不开数据流(Stream),而且是刚需。尤其做可信数据空间、数据沙箱、数据要素流通,高质量数据集 = 必须用 Stream。
(一)、高质量数据集为什么要用到 Stream?
高质量数据集的核心要求:实时、增量、去重、清洗、脱敏、合规、可追溯、低延迟
这些能力,只有流式计算能满足,批处理(离线同步)做不到或做得很差。
数据要 “新鲜”,才配叫高质量:
业务库持续写入、日志不断产生、IoT 实时上报
要保证数据集最新、最准、无延迟
→ 必须用 Stream 实时接入(CDC / MQ)
(二).数据清洗、脱敏、去重必须在线做
高质量数据集要求:
去重
缺失值填充
异常值剔除
敏感信息脱敏(身份证、手机号、地址)
格式标准化
这些边产生边处理,用 Flink / Spark Streaming 流式处理最稳。
离线批处理会有如下问题:
重复计算
延迟高
回溯成本高
(三)可信数据空间要求 “全程可追溯”
数据流可以做到:
每条数据携带血缘
接入→清洗→脱敏→标注→入仓全链路追踪
审计日志实时上链
批处理很难做到细粒度追踪。
大流量场景下,只有 Stream 扛得住
千万级 / 亿级数据持续写入
高并发、高吞吐
→ 必须用流式架构,否则数据库直接打挂。
三、高质量数据集场景应用数据流 Stream
(一)应用场景
动态更新的指标库、标签库
实时数仓(DWD/DWS 层高质量数据集)
AI 训练用的实时增量样本库
监管、合规、审计类数据集
可信数据空间对外提供的 “可交易高质量数据集”
这些场景不用 Stream,基本达不到 “高质量” 标准。
(二)哪些场景可以暂时不用 Stream?
只有一种:静态、封闭、一次性、稳定性较高、不会再更新的小数据集,可以通过API、文件等传统方式流通。
比如:
历史归档数据
一次性普查数据
固定样本集
但这种在数据要素、数据空间里基本不算主流。
四、结合应用的形态与方式
1. 接入连接器内置 Stream 能力(标配)
集成消息队列:Kafka/Pulsar/RocketMQ 作为流中间件
流处理引擎:Flink/Spark Streaming 做实时清洗、脱敏、过滤、格式转换
安全流通道:TLS / 国密加密、身份认证、策略随流执行
2. 典型数据流链路(TDS 标准流程)
数据源(DB/日志/IoT)→ 接入连接器(Stream接入+策略执行+脱敏)→ 消息队列(Kafka)→ 跨连接器P2P安全传输 → 使用方连接器(Stream消费+合规审计)→ 应用/隐私计算
3. 关键结合点
流接入:连接器提供 Stream 协议(MQTT/Kafka),支持实时数据上链
流控制:在流中嵌入使用控制策略、合约规则、权限校验,拒绝违规流数据
流审计:每条流记录不可篡改日志,支持事后追溯与计量
流交付:支持实时流订阅、批量流导出、API + 流混合交付
五、实时数据流Stream的技术选型
目前实时数据流(Stream)的主流方案,按消息队列 / 事件总线、流处理计算引擎、云托管服务、CDC 数据捕获四大类划分,覆盖从数据采集、传输到计算的全链路,以下是 目前最主流、最推荐的选型。
(一)消息队列 / 事件总线(数据流 “管道”)
负责实时数据的采集、缓冲、持久化与分发,是流架构的核心底座。
1. Apache Kafka(绝对主流)
核心定位:分布式、高吞吐、可持久化的事件流平台,构建实时数据管道与流处理应用的事实标准。
关键特性
高吞吐、低延迟:单机可达百万级 TPS,延迟毫秒级。
分布式、高可用:多副本、分区、故障自动转移。
持久化存储:数据可回溯、可重放,支持流与批统一访问。
生态完善:Kafka Connect(数据集成)、Schema Registry(Schema 管理)、ksqlDB(流 SQL)。
适用场景:日志收集、用户行为分析、微服务事件驱动、CDC 数据同步、实时数仓入湖。
托管版:Confluent Cloud、阿里云 Kafka、腾讯云 CKafka、AWS MSK、Azure Event Hubs(兼容 Kafka)。
2. Redpanda(Kafka 兼容新秀)
核心定位:兼容 Kafka API 的新一代流平台,用 C++ 重写,无 JVM、无 ZooKeeper,性能与运维成本更优。
关键特性:兼容 Kafka 生态、更低延迟、更高吞吐、更少资源占用、简化部署。
适用场景:追求极致性能、希望降低 Kafka 运维成本的场景。
3. Pulsar(存算分离架构)
核心定位:云原生、多租户、存算分离的流消息平台,由 Yahoo 开源,后捐给 Apache。
关键特性:存算分离、无限容量、强一致性、多租户、跨地域复制、支持队列与流两种模型。
适用场景:多云 / 混合云、跨地域部署、多租户 SaaS 平台、需要无限存储的流场景。
(二)流处理计算引擎(数据流 “计算大脑”)
对实时数据流进行转换、聚合、join、窗口、CEP 等复杂计算,输出实时结果。
1. Apache Flink(流处理王者,首选)
核心定位:原生流处理、流批一体的分布式计算引擎,真正的实时计算标杆。
关键特性
真正流处理:逐条事件处理,毫秒级延迟(50–200ms)。
强大状态管理:内置 StateBackend,支持海量状态与Exactly-Once语义。
事件时间 + 水位线:完美处理乱序数据,结果准确。
流批统一:同一引擎处理无界流与有界批,API 统一。
丰富 API:DataStream(Java/Scala/Python)、Table API、Flink SQL、CEP。
适用场景:实时数仓、实时风控、实时推荐、实时监控、实时报表、物联网实时分析、复杂事件处理。
托管版:阿里云实时计算 Flink、腾讯云 Oceanus、AWS Kinesis Data Analytics、Azure Stream Analytics(兼容 Flink)。
2. Spark Structured Streaming(Spark 生态首选)
核心定位:基于 Spark 引擎的微批流处理,将流视为无界表,提供与批处理一致的 API。
关键特性
与 Spark 生态无缝集成:Spark SQL、MLlib、GraphX、Delta Lake。
高吞吐、容错强,学习曲线平缓(熟悉 Spark 即可上手)。
支持事件时间、窗口、Exactly-Once。
延迟:秒级(通常 100ms–1s),不适合极致低延迟场景。
适用场景:已有 Spark 技术栈、需要流批一体、对延迟要求不苛刻的大规模实时处理。
3. Kafka Streams(轻量级流处理,Kafka 原生)
核心定位:轻量级客户端库,直接在 Kafka 集群上构建流应用,无需独立流处理集群。
关键特性
无外部依赖,仅需 Kafka 集群,部署简单。
与 Kafka 深度集成,Exactly-Once 语义一致。
水平扩展、状态管理、窗口、join 均支持。
适用场景:简单 ETL、数据过滤 / 转换 / 轻聚合、Kafka Topic 间实时处理、微服务内流逻辑。
4. Apache Storm(老牌低延迟)
核心定位:最早开源的纯实时流框架,专注极致低延迟(~10ms)。
特点:Tuple 逐条处理、无状态为主、At-Least-Once 语义(需额外保证 Exactly-Once)。
现状:社区活跃度下降,新项目更推荐 Flink。
(三)云厂商托管实时流服务(开箱即用,免运维)
适合不想自建集群、追求快速上线的场景。
1. AWS
Kinesis Data Streams:托管消息队列,类似 Kafka。
Kinesis Data Analytics:托管 Flink,SQL/Java 流处理。
Managed Streaming for Kafka (MSK):全托管 Kafka 集群。
2. Azure
Event Hubs:托管事件总线,兼容 Kafka。
Stream Analytics:低代码 SQL 流处理,支持 Flink。
3. 阿里云
消息队列 Kafka 版:托管 Kafka。
实时计算 Flink:全托管 Flink 平台,支持 SQL/Java/Python。
4. 腾讯云
CKafka:托管 Kafka。
流计算 Oceanus:全托管 Flink,亚秒延迟。
(四)CDC 实时数据捕获(数据库→流的入口)
将数据库变更实时捕获为流,是实时数仓、数据同步的核心入口。
1. Debezium(最主流开源 CDC)
核心定位:基于 Kafka Connect 的 CDC 工具,捕获 MySQL、PostgreSQL、MongoDB、SQL Server 等变更,输出到 Kafka。
关键特性:支持快照 + 增量、Exactly-Once、Schema 自动注册、高可用。
适用场景:数据库实时同步、CDC 入湖、微服务数据分发。
2. Maxwell、Canal
Maxwell:轻量级 MySQL CDC,输出到 Kafka/Kinesis。
Canal:阿里开源,专注 MySQL CDC,广泛用于国内。
(五)主流方案选型
(六)典型技术栈组合
通用实时数仓 / 数据湖
采集:Debezium(CDC)+ 日志 / 埋点 → Kafka
处理:Flink(SQL/Java)做实时 ETL、聚合、join
存储:Iceberg/Hudi/Delta Lake + ClickHouse/Doris
Kafka 生态轻量流
Kafka + Kafka Streams:无需独立集群,快速实现 Topic 间实时处理
Spark 生态流批一体
Kafka + Spark Structured Streaming:已有 Spark 集群,流批统一处理
极致云原生 / 免运维
云托管 Kafka + 云托管 Flink(如阿里云实时计算 Flink)
(七)选型关键决策点
延迟要求:极致低延迟(<200ms)→ Flink;秒级可接受 → Spark Streaming;轻量简单 → Kafka Streams。
技术栈:已有 Spark → Spark Streaming;深度依赖 Kafka → Kafka Streams;全新架构 → Flink + Kafka。
运维能力:自建 → Kafka + Flink;免运维 → 云托管服务。
数据来源:数据库变更为主 → Debezium + Kafka;日志 / 埋点为主 → Kafka + Flink。
六、Flink CEP应用到可信数据空间数字合约
以动态规则 + 事件驱动 + 合规闭环为核心,将 Flink CEP 作为可信数据空间数字合约的实时履约引擎,承接合约策略的动态下发、事件序列的实时匹配、违规行为的即时阻断与履约状态的自动上报,实现数据流通 “可用不可见、可控可审计、合规可追溯”。
(一)方案背景与核心价值
1. 可信数据空间数字合约核心诉求
数字合约是可信数据空间的核心规则载体,需覆盖合约创建 - 协商签署 - 备案 - 履行 - 终止全生命周期,核心诉求包括湖北省数据局:
细粒度策略:支持时间、地域、次数、算法、加密方式等 19 类约束条件,区分 “允许 / 禁止 / 义务” 三类规则;
动态履约:数据操作事件实时触发合约校验,毫秒级响应合规要求;
全链路追溯:所有匹配与操作留痕,支持事后审计与争议仲裁;
动态规则迭代:合约策略无需重启作业即可更新,保障业务连续性。
2. Flink CEP 的适配价值
Flink CEP 通过Pattern API实现复杂事件序列识别,结合动态 CEP 能力可无缝承接数字合约诉求:
事件序列匹配:精准识别 “数据请求→权限校验→违规操作” 等合约约定的行为序列;
动态规则加载:从配置中心 / 数据库实时拉取合约策略,无需重启作业;
低延迟高吞吐:毫秒级处理海量数据操作事件,支撑高并发数据流通;
状态与容错:Exactly-Once 语义保障履约状态不丢失,Checkpoint 机制支持故障恢复。
(二)整体架构设计
采用“数据接入 - CEP 匹配 - 合约执行 - 合规闭环”** 四层架构,与可信数据空间的隐私计算、区块链、使用控制技术深度融合。
关键技术融合点
与隐私计算融合:数据操作事件在密态环境下采集,CEP 匹配过程基于密态数据或脱敏结果,确保 “数据可用不可见”;
与智能合约融合:Flink CEP 输出匹配结果,触发智能合约自动执行(如权限回收、费用结算、违约惩罚);
与使用控制融合:CEP 匹配到违规行为时,立即调用使用控制接口阻断操作,实现 “事前可控”。
(三)核心流程设计
1. 数字合约全生命周期流程
合约创建与备案:数据提供方 / 使用方通过平台模板创建合约,策略中心存储合约规则(含事件序列、约束条件、执行动作),并将合约信息上链存证;
策略动态下发:策略中心将合约规则实时推送给 Flink CEP 作业,支持动态更新,无需重启作业;
事件实时采集:Flink CDC 捕获数据操作变更事件(如 MySQL binlog),封装为统一格式事件流发送至 Kafka;
CEP 规则匹配:Flink CEP 从 Kafka 消费事件,基于动态合约规则匹配事件序列,判断是否符合合约约定;
合约自动执行:
合规匹配:更新合约履约状态,上报审计平台,触发后续数据流转;
违规匹配:调用使用控制接口阻断操作,记录违约日志,触发智能合约惩罚机制;
全链路追溯:所有匹配结果、操作日志、履约状态上链,支持审计与争议仲裁。
2. 核心业务场景流程
场景 1:数据共享合规校验
合约规则:数据使用方仅可在 “指定时间窗口 + 指定地域 + 不超过 10 次读取” 范围内读取数据,禁止批量导出;
CEP 匹配逻辑:
执行动作:合规则记录履约状态;违规则阻断导出操作,触发违约通知并上链存证。
场景 2:数据交易自动结算
合约规则:数据使用方读取数据满 1 小时后,自动触发费用结算,结算失败则暂停数据访问;
CEP 匹配逻辑:按照业务需求进行数据流的动态匹配
执行动作:CEP 匹配到时间窗口后,触发智能合约结算,结算成功则更新履约状态;失败则暂停访问并通知双方。
(四)关键技术实现方案
1. 动态 CEP 规则加载(核心)
采用 “规则中心 + 动态发现器”模式,实现合约规则与业务代码解耦:
规则存储:将合约规则(事件序列、约束条件、窗口时间、执行动作)存储在 MySQL/PostgreSQL,字段设计如下:
动态发现器:自定义 PatternProcessorDiscoverer,定时从规则中心拉取最新规则,解析为 Flink CEP Pattern;
作业实现:使用 Flink 动态 CEP API(CEP.dynamicPatterns)加载规则,2. 事件标准化设计
2.为适配多源数据操作事件,定义统一的DataAccessEvent事件结构,确保 CEP 匹配兼容性:
3. 合规闭环实现
违规阻断:Flink CEP 匹配到违规行为时,通过 gRPC/HTTP 调用使用控制平台接口,立即终止操作并返回拒绝响应;
履约上报:合规匹配结果发送至审计平台,生成履约日志,日志字段包含事件 ID、合约 ID、操作主体、时间、结果等,支持全链路追溯;
智能合约联动:匹配结果触发智能合约执行,如费用结算、权限回收、违约惩罚,执行结果同步至区块链节点存证。
(五)性能与安全保障
1. 性能优化
规则优化:将复杂合约规则拆分为多个子规则,并行匹配,提升处理效率;
状态管理:合理设置状态 TTL,清理过期事件状态,减少内存占用;
并行度配置:根据数据吞吐量配置 Flink 作业并行度,建议 Kafka 消费并行度与分区数一致;
本地部署优化:要求配置足够内存(≥16G),关闭不必要的日志输出,提升 Flink CDC 与 CEP 作业性能。
2. 安全保障
数据安全:事件采集与匹配过程采用 TLS 1.3 加密,数据操作事件基于密态数据或脱敏结果;
规则安全:规则中心采用 RBAC 权限控制,仅合约管理员可更新规则,防止恶意规则注入;
操作留痕:所有 CEP 匹配结果、执行动作、违规记录上链,确保不可篡改,支持审计;
国密算法:合约信息、事件签名采用国密算法(SM2/SM3/SM4),符合国内合规要求。
七、基于Flink SQL的可视化工具选型
目前有开源的可视化操作自动生成 Flink SQL方案, 基于这些方案选型进行二开是较为稳妥的技术路线。
(一)主流开源方案(按成熟度排序)
1. Dinky(原 Dlink,最推荐)
核心能力:拖拽式画布 + 表单配置 → 自动生成完整 Flink SQL(含CREATE TABLE+INSERT+WITH 参数)
关键特性
拖拽 Source/Sink/ 算子节点,连线构建流
表单配置连接器、字段映射、窗口、JOIN
自动生成标准 Flink SQL,支持预览 / 校验 / 执行
支持 CDC、维表关联、CEP、流批一体
内置大量场景模板(实时统计、CDC 同步、大屏)
适合:生产级、低代码、全链路 Flink SQL 开发
2. StreamX(原 StreamPark)
核心能力:可视化 SQL 编辑器 + 表单配置 → 生成 / 提交 Flink SQL
关键特性
图形化 SQL 编辑、语法提示、格式化、校验
表单配置作业参数、Checkpoint、并发
一键提交到 YARN/K8s,支持 SavePoint
作业监控、告警、版本管理
适合:企业级 Flink 作业管理、SQL 开发 + 运维一体化
3. PiflowX
核心能力:纯拖拽式低代码 → 自动生成 Flink SQL
关键特性
拖拽组件(MySQL CDC、Kafka、Hologres、聚合、窗口)
右侧表单填参数 → 自动生成 Flink SQL
基于 Flink Table API,兼容标准语法
适合:零代码、快速搭建简单实时任务
4. flink-streaming-platform-web
核心能力:表单配置 → 生成 Flink SQL + 任务管理
开源地址:https://github.com/zhp8341/flink-streaming-platform-web
关键特性
轻量、开箱即用
表单配置 Source/Sink、SQL 逻辑
自动生成 SQL,支持语法校验、格式化
任务启停、日志、告警
适合:轻量场景、快速验证 SQL 逻辑
5. Flink SQL Gateway + 自研前端(最灵活)
核心能力:官方 SQL Gateway + 自定义拖拽 / 表单 → 生成 SQL
开源基础:Flink 官方 SQL Gateway(内置)
实现路径
部署 Flink SQL Gateway(提供 REST API)
前端:React/Vue 做拖拽画布 + 表单
后端:节点配置 → 映射为 Flink SQL AST → 生成 SQL
调用 Gateway 执行 / 提交
适合:需要深度定制、集成到自有平台
(二)技术实现原理(开源通用)
所有开源方案的自动生成逻辑基本一致:
可视化层:拖拽节点 / 填表单 → 生成配置 JSON(源 / 目标、字段、窗口、过滤、JOIN)
映射引擎:配置 → 按规则生成 Flink SQL 片段
Source/Sink → CREATE TEMPORARY TABLE ... WITH (...)
过滤 → WHERE ...
聚合 / 窗口 → GROUP BY TUMBLE(...)
维表关联 → LOOKUP JOIN ... FOR SYSTEM_TIME AS OF ...
AST 校验:用 Calcite 解析 AST,做语法 / 逻辑校验
输出:完整可执行 Flink SQL
(三)方案对比
(四)快速落地建议
优先选 Dinky:拖拽 + 表单 + 自动 SQL + 生产运维,一站式搞定
快速验证:本地部署 Dinky,拖入 MySQL CDC→Kafka,填参数,一键生成 SQL 并执行
定制化:用 Flink SQL Gateway 做二次开发,集成到内部平台
七、推荐落地应用架构
(一)结合应用架构
通过数据源MySQL/Oracle →Flink SQL/ CDC(Flink CDC)→ Stream 清洗/脱敏/去重 → 高质量主题库 → 数据沙箱/可信数据空间,这是目前省级信创、数据交易所、政务数据空间最标准的高质量数据集生产链路。
高质量数据集 ≠ 静态文件,高质量数据集 = 持续、干净、新鲜、合规的数据流
在可信数据空间里:
接入连接器 + Stream 流处理 = 高质量数据集的生产流水线
接入连接器:Sidecar 模式,内置 Flink SQL 数据流作业客户端 + Flink 轻量级流处理
流中间件:Flink集群,做流实时传输、削峰填谷、跨域传输
流安全:国密加密 + 身份认证 + 策略引擎,流数据全程受控
流审计:区块链存证 + 日志系统,全链路可追溯
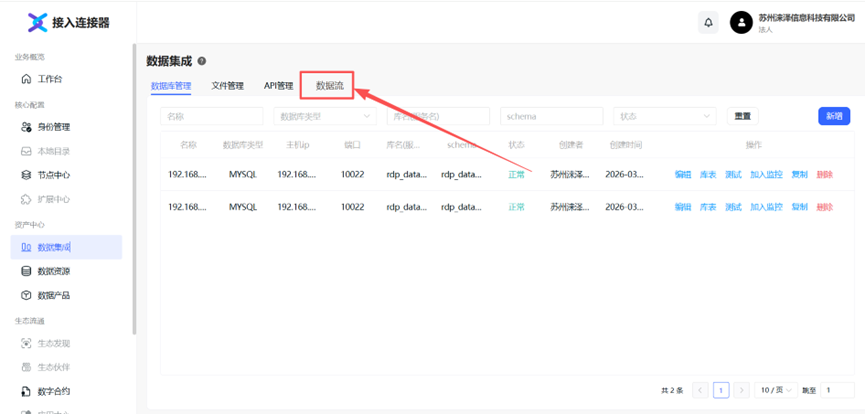
(二)现有接入连接器改造
现有接入连接器的数据集成功能增加“数据流”接入,可支持数据提供方(高质量数据集)采用实时数据流的方式为数据使用方提供实时的高质量数据。
另外结合第六章的Flink SQL可视化拖曳,支持对源库、目标库的可视化配置,包括对数据库字段的选择、过滤、聚合(求和、求平均、最大值、最小值等)、各类Flink算子如对map、flatmap、filter、keyBy、shuffle、rescale、并流、分流等的可视化操作。
欢迎访问 小易撩挨踢