
SpringBoot 生态下中文分词框架均基于 Java 开发,可快速集成实现文本拆分、关键词提取、语义预处理等能力,广泛用于全文检索、内容审核、舆情分析、智能标签等业务。

下文详细介绍 7 款主流框架,涵盖功能、特点、优劣及应用场景。
一、IK 分词器
核心功能
专为检索场景设计的轻量级分词组件,支持智能分词与最大细粒度分词双模式,内置基础词典、停用词过滤,支持自定义业务词典、热更新词典,可过滤无意义虚词,适配文本检索拆分需求。
核心特点
原生深度适配 Elasticsearch,是 SpringBoot 整合 ES 做搜索的标配;
接入极简,仅需引入 Maven 依赖即可使用,无额外环境依赖;
分词模式固定:
ik_smart精简短句分词,ik_max_word穷尽所有拆分词汇。
优缺点
优点:社区体量最大、文档丰富、运维成本低;运行稳定、内存占用小;自定义词典配置简单,业务热词可快速录入;检索匹配准确率高。
缺点:仅具备基础分词能力,无词性标注、实体识别、文本摘要等进阶 NLP 功能;对网络新词、流行语识别能力弱;无法解析文本语义逻辑。
应用场景
SpringBoot 电商商品搜索、站内全文检索、日志关键词拆分、后台内容关键词过滤、简单站内搜索系统,是企业检索类项目首选分词框架。
二、HanLP
核心功能
Java 生态全能型离线 NLP 分词框架,不止基础分词,一站式集成词性标注、命名实体识别、关键词提取、文章自动摘要、繁简体转换、拼音标注、情感倾向初步判断等数十项文本处理能力。
核心特点
纯 Java 编写,零第三方依赖,SpringBoot 无缝自动装配,离线即可运行;
划分极速版与标准版,轻量场景用极速版提速,精准场景用标准版;
内置百万级通用词典,支持行业专属词典、自定义模型训练。
优缺点
优点:功能最全,替代多款轻量分词组件;分词综合准确率高,适配口语、书面语;开源免费、持续迭代更新;部署无需搭建独立服务,嵌入项目即可使用。
缺点:超大批量文本并发处理速度弱于专用高速分词器;高阶语义分析需加载额外模型文件,增加项目体积;深度语义推理能力有限。
应用场景
SpringBoot 内容管理系统、用户评论舆情分析、文章智能标签生成、政务文本整理、短视频文案解析、简单内容风控审核,中小型项目一站式文本处理首选。
三、Jieba Java 分词(结巴分词)
核心功能
Python 热门结巴分词的 Java 移植版本,支持精准模式、全模式、搜索引擎模式三类分词逻辑,具备词性标注、高频关键词抽取、新词自动发现、自定义词典加载能力。
核心特点
贴合日常口语表达习惯,分词逻辑贴近大众用语,对网络流行词、短句口语拆分效果优秀,开源轻量化,接口调用简洁。
优缺点
优点:口语化文本分词精度极高;三种模式覆盖日常大部分文本场景;学习成本低,跨语言业务可统一分词规则。
缺点:Java 移植版性能低于原生 Python 版本;高并发海量文本处理吞吐量不足;国内社区活跃度偏低,疑难问题解决方案较少。
应用场景
SpringBoot 社交平台评论分词、自媒体文案关键词提取、短视频标题解析、个人轻量化文本工具类项目。
四、Ansj 分词
核心功能
基于隐马尔可夫算法打造的高性能分词框架,主打高速文本拆分,支持索引分词、精准分词、停用词过滤、词性简单标注,可自定义分词过滤规则。
核心特点
极致优化并发性能,流式文本拆分效率顶尖,内存占用极低,专为大数据批量文本预处理设计,SpringBoot 仅需少量配置即可接入。
优缺点
优点:高并发、大流量场景下性能碾压多数通用分词框架;代码简洁,无冗余功能;适合离线批量文档分词。
缺点:功能极度单一,仅聚焦分词,无任何进阶 NLP 能力;官方文档简略,拓展性差;行业定制化支持薄弱。
应用场景
SpringBoot 大数据日志分析系统、海量文档批量预处理、高并发消息流文本拆分、离线大数据文本清洗项目。
五、MMseg4j
核心功能
老牌经典 Java 分词框架,依托 MMseg 分词算法实现基础中文拆分,适配 Lucene、Solr 传统检索引擎,支持简易自定义词典配置。
核心特点
技术架构老旧但算法成熟,兼容低版本 Java 环境,适配传统老旧检索项目架构。
优缺点
优点:运行稳定无 BUG,老项目兼容度拉满;部署零门槛,无复杂依赖。
缺点:长期停止维护,无版本更新;分词精度落后主流框架;不识别新词、网络用语;无任何拓展 NLP 功能。
应用场景
仅用于老旧 SpringBoot 项目迭代维护、传统 Lucene 检索系统改造,新项目禁止选用。
六、THULAC 清华分词
核心功能
清华大学开源学术级分词工具,Java 封装接口实现分词 + 词性联合精准标注,针对正式书面文本做深度优化,适配规范句式拆分。
核心特点
依托学术深度学习模型研发,分词逻辑严谨,公文、文献类文本解析精度行业顶尖。
优缺点
优点:正式书面语、学术文本分词准确率位居前列;词性标注严谨规范。
缺点:依赖外部独立模型文件,项目部署繁琐;SpringBoot 集成流程复杂;模型加载耗时久,不支持高并发业务;资源占用偏高。
应用场景
SpringBoot 教育行业文献解析、政府公文文本处理、学术资料整理等正式书面文本业务。
七、LTP 哈工大语言技术平台
核心功能
工业级深度 NLP 框架,Java 可调用本地模型或云端接口,涵盖分词、词性标注、句法依存分析、语义角色标注、领域实体抽取等全链路深度文本处理能力。
核心特点
国内顶尖语义分析框架,可解析长文本复杂句式、逻辑语义,适配高阶 AI 文本业务。
优缺点
优点:深度语义理解能力最强,复杂长文本、专业领域文本解析效果优异;支持多领域实体抽取。
缺点:本地部署模型体积庞大,服务器资源消耗极高;云端调用存在网络延迟与接口限制;SpringBoot 集成难度大,轻量化项目过于臃肿。
应用场景
SpringBoot 智能问答系统、法律文书解析、专业领域文本语义分析、高端 AI 内容理解项目。
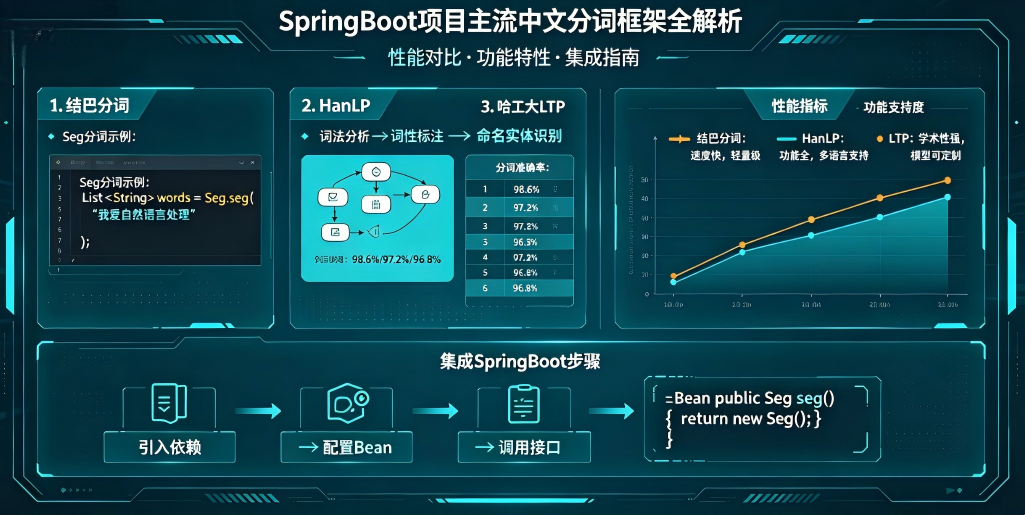
项目选型精简建议
做搜索检索业务:优先IK 分词;
一站式全功能文本处理:优先HanLP;
高并发海量文本清洗:优先Ansj 分词;
口语社交文本解析:选用Jieba 分词;
正式公文学术文本:选用THULAC;
高阶语义 AI 业务:选用LTP。
所有框架均可无缝集成 SpringBoot,仅需引入对应 Maven 依赖,编写简单工具类即可快速调用,可根据业务轻量化、高性能、高精度三类需求灵活取舍。
原文链接
欢迎访问 小易撩挨踢